Good Workflow Practices for Reproducible Data Science
Dr. Mine Dogucu
Naming files
Three principles of naming files
machine readable
human readable
plays well with default ordering (e.g. alphabetical and numerical ordering)
(Jenny Bryan)
for the purposes of this course an additional principle is that file names follow
tidyverse style (all lower case letters, words separated by HYPHEN)
README.md
README file is the first file users read. In our case a user might be our future self, a teammate, or (if open source) anyone.
There can be multiple README files within a single directory: e.g. for the general project folder and then for a data subfolder. Data folder README’s can possibly contain codebook (data dictionary).
It should be brief but detailed enough to help user navigate.
a README should be up-to-date (can be updated throughout a project’s lifecycle as needed).
On GitHub we use markdown for README file (README.md). Good news: emojis are supported.
Microsoft products have Copyright. Images used based on fair use for educational purposes.
R Packages
Optional
R packages
When you download R, you actually download base R.
But there are MANY optional packages you can download.
Good part: There is an R package for (almost) everything, from complex statistical modeling packages to baby names.
Bad part: At the beginning it can feel overwhelming.
All this time we have actually been using R packages.
R packages
What do R packages have? All sorts of things but mainly
functions
datasets
R packages
Try running the following code:
beep()
Error in beep(): could not find function "beep"
Why are we seeing this error?
Installing packages
Using install.packages()
In your Console, install the beepr package
install.packages("beepr")
We do this in the Console because we only need to do it once.
Using Packages pane
Packages Pane > Install
Letting RStudio Install
If you save your file and using a package RStudio will tell you that you have not installed the package.
Using packages
Using beep() from beepr
Option 1
library(beepr)beep()
More common usage.
Useful if you are going to use multiple functions from the same package. E.g. we have used many functions (ggplot, aes, geom_…) from the ggplot2 package. In such cases, usual practice is to put the library name in the first R chunk in the .Rmd file.
Using beep() from beepr
Option 2
beepr::beep()
Useful when you are going to use a function once or few times. Also useful if there are any conflicts. For instance if there is some other package in your environment that has a beep() function that prints the word beep, you would want to distinguish the beep function from the beepr package and the beep function from the other imaginary package.
Open Source
Any one around the world can create R packages.
Good part: We are able to do pretty much anything R because someone from around the world has developed the package and shared it.
Bad part: The language can be inconsistent.
Good news: We have tidyverse.
Tidyverse
The tidyverse is an opinionated collection of R packages designed for data science. All packages share an underlying design philosophy, grammar, and data structures. tidyverse.org
Tidyverse
In short, tidyverse is a family of packages. From practical stand point, you can install many tidyverse packages at once (and you did this).
We can also load multiple tidyverse packages all at the same time.
library(tidyverse)
── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.3 ✔ readr 2.1.4
✔ forcats 1.0.0 ✔ stringr 1.5.0
✔ ggplot2 3.4.4 ✔ tibble 3.2.1
✔ lubridate 1.9.3 ✔ tidyr 1.3.0
✔ purrr 1.0.2
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
Exercise
Refer back to older slides and identify the packages for each of the functions we commonly use in this class.
Importing data will depend on where the dataset is on your computer. However we use the help of here::here() function. This function sets the working directory to the project folder (i.e. where the .Rproj file is).
read_csv(here::here("data/dataset.csv"))
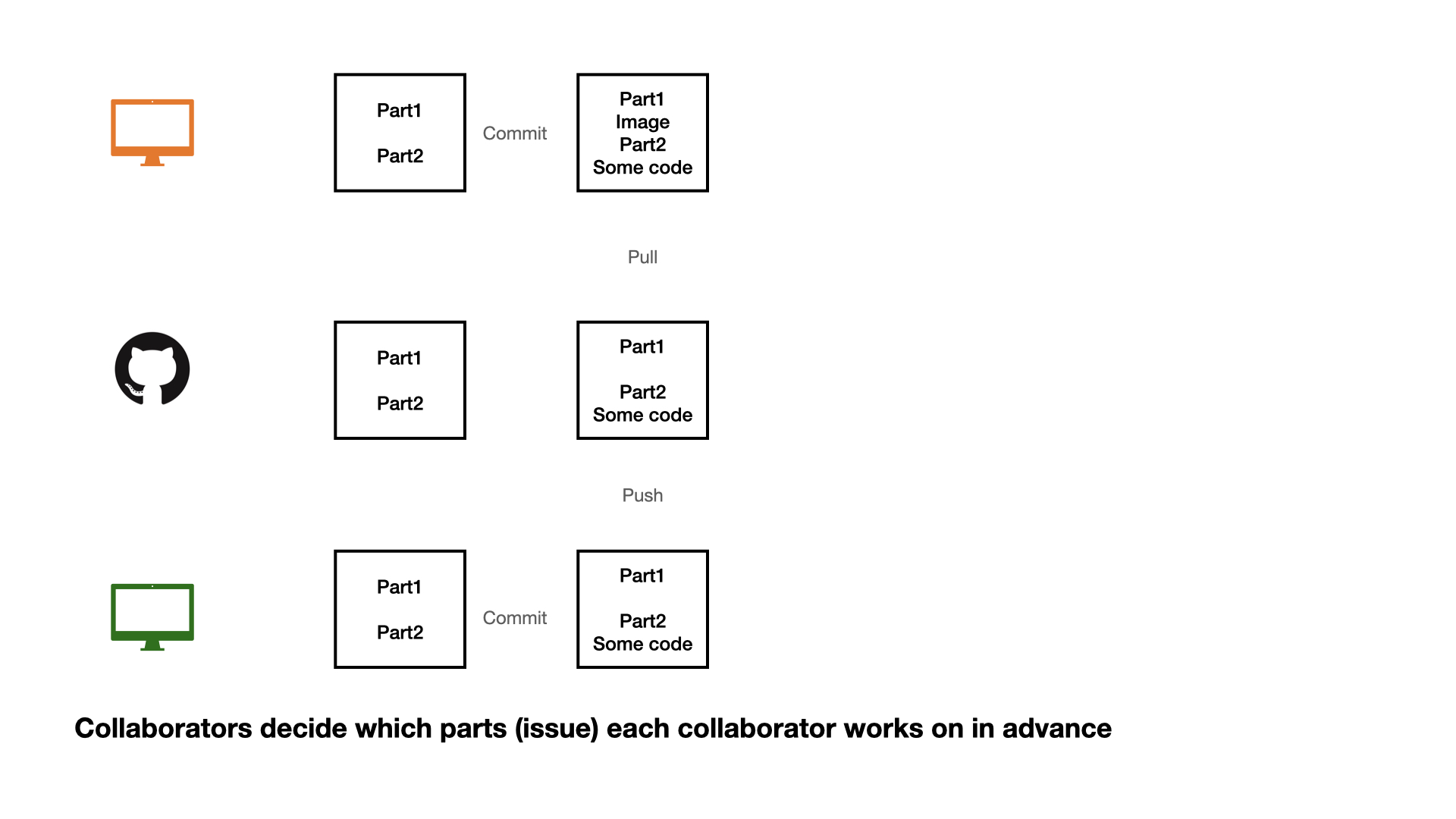
Collaboration on GitHub
Collaboration on GitHub
Collaboration on GitHub
Collaboration on GitHub
Collaboration on GitHub
Collaboration on GitHub
Collaboration on GitHub
Collaboration on GitHub
If each change is made by one collaborator at a time, this would not be an efficient workflow.
Collaboration on GitHub
Collaboration on GitHub
Collaboration on GitHub
Collaboration on GitHub
1 - commit
2 - pull (very important)
3 - push
Collaboration on GitHub
Collaboration on GitHub
Collaboration on GitHub
Opening an issue
We can create an issue to keep a list of mistakes to be fixed, ideas to check with teammates, or note a to-do task. You can assign tasks to yourself or teammates.
Closing an issue
If you are working on an issue, it makes sense to refer to issue number in your commit message (e.g. “add first draft of alternate texts for #4”). If your commit resolves the issue then you can use key words such as “fixes #4” or “closes #4” to close the issue. Issues can also be manually closed.
.gitignore
A .gitignore file contains the list of files which Git has been explicitly told to ignore.
For instance README.html can be git ignored.
You may consider git ignoring confidential files (e.g. some datasets) so that they would not be pushed by mistake to GitHub.
A file can be git ignored either by point-and-click using RStudio’s Git pane or by adding the file path to the .gitignore file. For instance weather.csv data file in a data folder need to be added as data/weather.csv
Files with certain files (e.g. all .log files) can also be ignored. See git ignore patterns.
It is also a good practice to save session information as package versions change, in order to be able to reproduce results from an analysis we need to know under what technical conditions the analysis was conducted.